🏥 KI-gestützte Pflegegutachten: Wie RAG die Genauigkeit (fast) verdoppelt
November 2025 | Lesezeit: ~8 Minuten
🎯 Worum geht es?
Die Pflegebegutachtung nach den Begutachtungsrichtlinien (BRi) ist komplex und erfordert fundiertes Fachwissen.
In diesem Artikel zeige ich, wie moderne KI-Modelle bei der Bewertung von Kriterien aus den Begutachtungsrichtlnien (BRi) am Beispiel von Modul 1 unterstützen können und warum die Kombination aus Retrieval-Augmented Generation (RAG) und spezialisiertem Prompt Engineering die Genauigkeit von 30% auf 68% steigern kann.
„Sweet Spot“ für RAG-Systeme in der Pflegebegutachtung. Sie übertreffen sogar GPT-4o und sind dabei
kostenlos und lokal nutzbar.
🔬 Die Methodik: Was wurde getestet?
Der Benchmark
Ich habe 100 Multiple-Choice-Fragen zum Modul 1 (Mobilität) der Pflegebegutachtung erstellt.
Jede Frage beschreibt eine realistische Pflegesituation und fragt nach der korrekten Bewertung
nach BRi (selbständig, überwiegend selbständig, überwiegend unselbständig, unselbständig).
Die getesteten Modelle
| Modell | Größe | Verfügbarkeit |
|---|---|---|
| Llama-4-Scout-17B | 17 Mrd. Parameter | Open-Source (Cloud + Lokal) |
| GPT-4o | ~100+ Mrd. Parameter | Closed-Source (OpenAI) |
| Teuken-7B | 7 Mrd. Parameter | Open-Source (Lokal) |
🔧 Technischer Hintergrund: Was ist RAG?
RAG (Retrieval-Augmented Generation) bedeutet, dass das KI-Modell nicht nur aus seinem trainierten
Wissen antwortet, sondern zusätzlich relevante Informationen aus einer Wissensdatenbank abruft.
In unserem Fall: Die offiziellen Begutachtungsrichtlinien und Spezialfälle aus der Praxis.
Hybrid Search: Kombination aus semantischer Suche (Bedeutung) und Keyword-Suche (BM25)
für optimale Ergebnisse.
Drei Test-Konfigurationen
- Baseline: Modell ohne zusätzliche Hilfe
- RAG (Standard): Modell + Wissensdatenbank
- RAG + Strikt: Modell + Wissensdatenbank + spezialisierter Prompt mit Beispielen
📊 Die Ergebnisse: Llama-4-Scout gewinnt
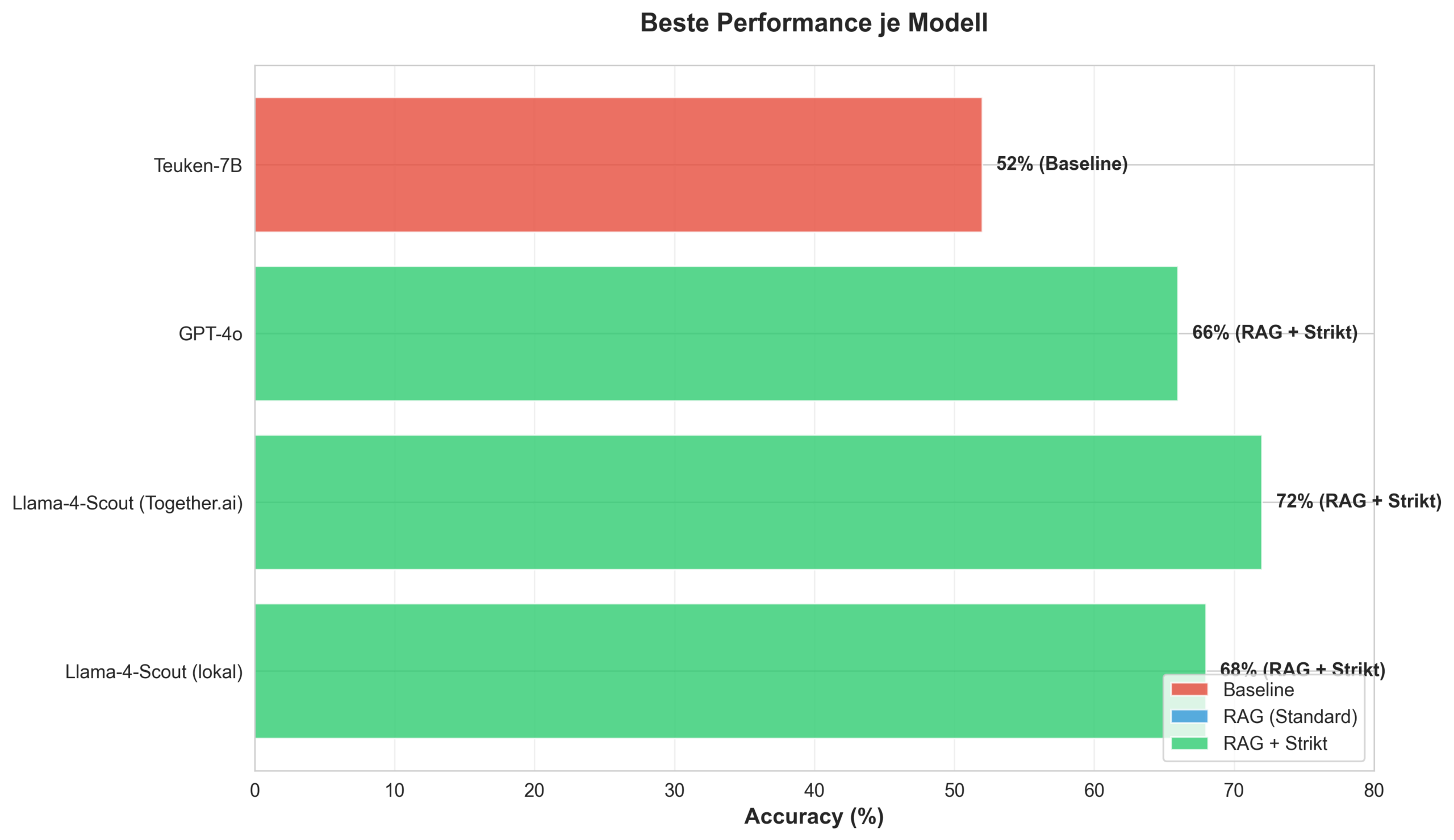
🏆 Das Ranking (beste Konfiguration)
| Platz | Modell | Genauigkeit | Konfiguration |
|---|---|---|---|
| 🥇 | Llama-4-Scout (Cloud) | 72% | RAG + Strikt |
| 🥈 | Llama-4-Scout (Lokal) | 68% | RAG + Strikt |
| 🥉 | GPT-4o | 66% | RAG + Strikt |
| 4 | Teuken-7B | 52% | Baseline (ohne RAG) |
📈 Die Detailanalyse: Warum funktioniert RAG so gut?

Llama-4-Scout (lokal): Der größte Gewinner
- Baseline: 30% Genauigkeit
- + RAG: 44% (+14 Prozentpunkte)
- + Strikter Prompt: 68% (+24 Prozentpunkte)
- Gesamt: +38 Prozentpunkte = mehr als Verdopplung!
GPT-4o: Solide, aber weniger Verbesserung
- Baseline: 51% (bereits gut)
- + RAG: 62% (+11 Prozentpunkte)
- + Strikter Prompt: 66% (+4 Prozentpunkte)
- Gesamt: +15 Prozentpunkte
⚠️ Teuken-7B: Ein Sonderfall
Das kleinere Teuken-Modell (7 Milliarden Parameter) zeigt ein unerwartetes Verhalten:
RAG verschlechtert die Ergebnisse von 52% auf 48%. Auch der strikte Prompt bringt keine Verbesserung.
Mögliche Erklärungen:
- Das Modell ist zu klein, um zusätzlichen Kontext sinnvoll zu verarbeiten
- Konfigurationsfehler in meinem Setup (weitere Tests nötig)
- Das Modell ist für diesen spezifischen Use Case ungeeignet
Fazit: Für produktive Pflegegutachten-Systeme ist Teuken-7B aktuell nicht empfehlenswert.
💡 Warum ist Llama-4-Scout so erfolgreich?
1. Die optimale Größe: Der „Sweet Spot“
Mit 17 Milliarden Parametern liegt Llama-4-Scout genau in der Mitte:
- Zu klein (<10B): Kann zusätzlichen Kontext nicht nutzen (siehe Teuken)
- Optimal (~17B): Perfekte Balance zwischen Kontext-Verarbeitung und Fokus
- Zu groß (>50B): Bereits ohne RAG sehr gut, weniger relativer Gewinn
2. Prompt Engineering wirkt besonders stark
Der spezialisierte Prompt mit Chain-of-Thought-Beispielen (z.B. zum „Prinzip Hilfsmittel“)
bringt bei Llama-4-Scout +24 Prozentpunkte, bei GPT-4o nur +4 Prozentpunkte.
Interpretation: Mittelgroße Modelle profitieren stärker von expliziten Anweisungen,
während sehr große Modelle diese Prinzipien bereits „verstanden“ haben.
3. Lokal vs. Cloud: Ein fairer Trade-off
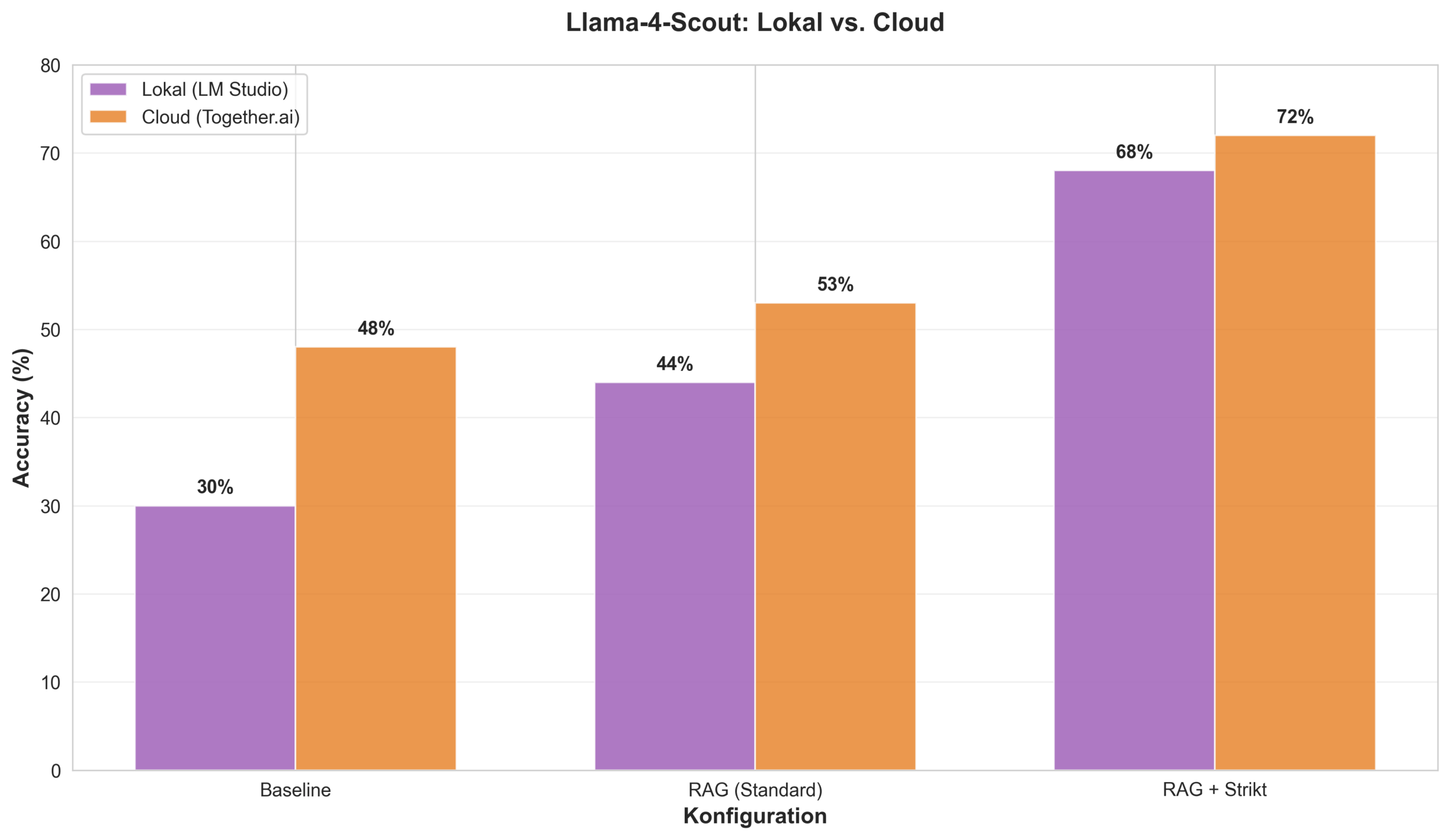
| Kriterium | Cloud (Together.ai) | Lokal (LM Studio) |
|---|---|---|
| Genauigkeit | 72% | 68% (-4%) |
| Geschwindigkeit | 1.5s/Frage | 6.2s/Frage |
| Kosten (100 Fragen) | ~0.20€ | Kostenlos |
| Datenschutz | Daten verlassen Server | 100% lokal |
| Reproduzierbarkeit | Abhängig vom Anbieter | Vollständig kontrollierbar |
Empfehlung: Für Forschung und Entwicklung ist die lokale Variante ideal
(kostenlos, reproduzierbar, datenschutzkonform). Für produktive Systeme mit hohem Durchsatz
kann die Cloud-Variante sinnvoll sein.
🎓 Fazit und Ausblick
Die wichtigsten Erkenntnisse
- Llama-4-Scout-17B ist das beste Modell für Pflegegutachten-Benchmarks
– es schlägt sogar GPT-4o und ist dabei Open-Source und lokal nutzbar. - RAG funktioniert hervorragend – die Genauigkeit steigt um bis zu 38 Prozentpunkte.
- Modellgröße ist entscheidend – ~17 Milliarden Parameter sind der Sweet Spot.
Kleinere Modelle (<10B) profitieren nicht von RAG. - Prompt Engineering verstärkt den Effekt – spezialisierte Prompts mit Beispielen
bringen bei mittelgroßen Modellen den größten Gewinn. - Lokale Nutzung ist praktikabel – mit nur 4% Genauigkeitsverlust gegenüber
der Cloud-Variante, dafür kostenlos und datenschutzkonform.
Nächste Schritte
- Erweiterung auf alle 6 Module der Pflegebegutachtung
- Test mit komplexeren Vignetten (nicht nur Multiple-Choice)
- Automatische Pflegegrad-Ermittlung aus Fallbeschreibungen
- Weitere Untersuchung des Teuken-Verhaltens (Konfiguration vs. Limitation)
📚 Technische Details
Software: LM Studio (lokal), Together.ai (Cloud), OpenAI API
RAG-System: ChromaDB + Hybrid Search (BM25 + OpenAI Embeddings)
Wissensbasis: Begutachtungsrichtlinien (BRi) + Spezialfälle Modul 1
Benchmark: 100 Multiple-Choice-Fragen, Modul 1 (Mobilität)
Code: Open-Source, verfügbar auf Anfrage





0 Kommentare